一起学netty(3)nio多路复用器select、poll、epoll理解
上一篇《一起学netty(2)nio模型及多路复用器》中已经简单介绍了nio模型,以及多路复用器的概念,并了解nio是非阻塞的网络模型,以及与bio的区别。本篇将继续深入理解nio,以及select、poll、epoll三种多路复用器。
两个角度讲nio
从操作系统的角度来讲,nio(nonblocking IO非阻塞io)是由操作系统提供的一套非阻塞的网络io模型,和一组提供给用户程序的系统调用(select、poll、epoll_create、epoll_ctl、epoll_wait等)。我们所说的select和poll、epoll都是操作系统提供的系统调用。
从java的角度来讲,nio(new IO)是java 1.4版本后引入的一套新的io体系,在java.nio包下。它的实现依赖于操作系统,不同的操作系统有不同的实现。
阻塞io的缺点
因为bio的监听客户端链接的方法和监听客户端发送消息的方法都是阻塞的,所以不得不为每个客户端链接都申请一个线程,让客户端链接在子线程中去监听消息。
当客户端很多时,客户端连接数(线程数)将会成为程序的性能瓶颈,操作系统再进行线程调度的时候会有一定的性能损耗(中断、线程的上下文切换等)。
非阻塞io诞生
为例解决阻塞io存在的缺陷,非阻塞io诞生了,nio在监听socket连接,以及监听消息收发的时候都不会阻塞,进而在处理socket连接和监听消息收发可以在一个线程中实现。如下:
public static final List<SocketChannel> socketChannels = new ArrayList<>();
public static void main(String[] args) throws Exception{
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(9000));
serverSocketChannel.configureBlocking(false);
while (true){
Thread.sleep(1000);
SocketChannel accept = serverSocketChannel.accept();
if(accept != null){
accept.configureBlocking(false);
socketChannels.add(accept);
System.out.println("建立链接成功:"+accept.socket().getPort());
}
Iterator<SocketChannel> iterator = socketChannels.iterator();
while (iterator.hasNext()){
SocketChannel next = iterator.next();
ByteBuffer buffer = ByteBuffer.allocate(128);
int read = next.read(buffer);
if(read > 0){
System.out.println(next.socket().getPort()+" 读取数据:"+new String(buffer.array()));
}else if(read == -1){
next.close();
System.out.println(next.socket().getPort()+" 链接关闭");
iterator.remove();
}
}
}
}
代码中可以看到,当有客户端连接的时候,首先要保存客户端的信息,然后再遍历所有的客户端,检查客户端是否有消息发送。
这种情况下,当客户端连接数很多并且有消息发送的客户端很少的时候,那么遍历没有消息发送的客户端将会产生性能损耗。因为read()方法内部会使用到系统调用,会让操作系统内核参与,所以势必会产生中断,导致用户态和内核态之间相互切换,影响性能。所以当客户端很多的时候,使用到系统调用就会很多,性能的影响就会越来越明显。
多路复用器select
上述中非阻塞io解决了阻塞io的缺点,但是非阻塞io本身还是存在一定的影响性能的问题。即每个客户端都会通过系统调用来确定客户端有没有发送消息,当客户端很多的时候系统调用就会越多。那么能不能通过一个系统调用就能获取所有的有消息发送的客户端呢,而不是遍历全部的客户端。操作系统为我们提供了这样一个系统函数。
函数格式:
int select(int nfds,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout)select 是一个系统调用函数,成功时返回就绪文件描述符总的个数(即 可读、可写和异常的就绪文件描述符)
nfds参数指定被监听的文件描述符的总数,readfds、writefds、execptfds参数分别指向可读、可写和异常事件对应的文件描述符集合应用程序调用select函数时,通过这3个参数传入自己感兴趣的文件描述符。select调用返回时,内核将修改他们来通知应用程序哪些文件描述符已经就绪。
通过这个系统调用函数,应用程序可以通过传入所有客户端的文件描述符来获取所有有数据收发(就绪)的客户端,进而遍历这些有数据收发(就绪)的客户端,进行数据的收发操作。那些没有数据收发的客户端将不会被操作。从而减少了系统调用的次数(没有数据收发的客户端不会被调用)。
select函数对一次传入的文件描述符有限制,默认值是1024个。
多路复用器Poll
函数格式:
int poll ( struct pollfd * fds, unsigned int nfds, int timeout);poll的机制与select类似,与select在本质上没有多大差别,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
多路复用器epoll
知道了select、poll多路复用器的缺点后,那么epll多路复用器就出现了。
Epoll的设计和select、poll有所不同。Epoll提供了三个核心的系统调用分别是:
- int epoll_create(int size)
- int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
- int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout)
关系图例如下:
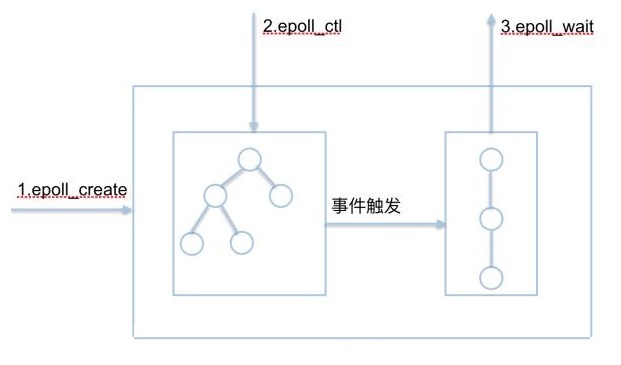
当程序启动的时候,会调用epoll_create,内核会产生一个epoll 实例数据结构并返回一个文件描述符,这个特殊的描述符就是epoll实例的句柄。当有客户端建立链接的时候会调用epoll_ctl,将客户端的文件描述符注册到epoll实例中,开始监听并告诉内核要监听什么事。 当事件发生的时候(比如有数据收发)这时操作系统会将文件描述符从红黑树中拷贝到链表当中,等待程序调用epoll_wait读取,如果调用epoll_wait的时候,链表中有数据则直接取走,否则将会进入阻塞,当然等待时间也由程序设定。
这样当每个客户端建立链接的时候只会调用一次epoll_ctl,调用epoll_wait也不用拷贝文件描述符到内核,解决了select、poll的缺点。并且将时间复杂度由O(n)降为O(1),不用再去遍历fd。从而最大限度的降低了性能的损耗。
以上就是我结合java的nio以及操作系统的相关知识来对select、poll、epoll的简单理解。当然了操作系统中对多路复用器的实现远比本文描述的要复杂得多,感兴趣的可以再进行深入的了解。