FCFS、SJF、HRRN调度算法
《操作系统》
先来先服务(FCFS, First Come First Serve)
算法思想:主要从“公平”的角度考虑(类似于我们生活中排队买东西的例子)
算法规则:按照作业/进程到达的先后顺序进行服务
用于作业/进程调度:用于作业调度时,考虑的是哪个作业先到达后备队列;用于进程调度时,考虑的是哪个进程先到达就绪队列。
是否可抢占?:非抢占式的算法
优缺点:
- 优点:公平、算法实现简单
- 缺点:排在长作业(进程)后面的短作业需要等待很长时间,带权周转时间很大,对短作业来说用户体验不好。即,FCFS算法对长作业有利,对短作业不利(Eg :排队买奶茶...)
是否会导致饥饿:不会
例题:各进程到达就绪队列的时间、需要的运行时间如下表所示。使用先来先服务调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
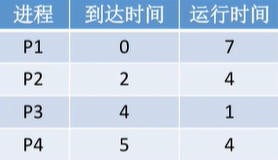
先来先服务调度算法:按照到达的先后顺序调度,事实上就是等待时间越久的越优先得到服务。因此,调度顺序为:P1 >P2 >P3>P4

周转时间=完成时间-到达时间
P1=7-O=7;P2=11-2=9;P3=12-4=8;P4=16-5=11
带权周转时间=周转时间/运行时间
P1=7/7=1;P2=9/4=2.25;P3=8/1=8;P4=11/4=2.75
等待时间=周转时间-运行时间
P1=7-7=O;P2=9-4=5;P3=8-1=7;P4=11-4=7
平均周转时间=(7+9+8+11)/4 =8.75
平均带权周转时间=(1+2.25+8+2.75)/4= 3.5平均等待时间=(0+5+7+7)/4= 4.75
短作业优先(SJF, Shortest Job First)
算法思想:追求最少的平均等待时间,最少的平均周转时间、最少的平均平均带权周转时间
算法规则:最短的作业/进程优先得到服务(所谓“最短”,是指要求服务时间最短)
用于作业/进程调度:即可用于作业调度,也可用于进程调度。用于进程调度时称为“短进程优先( SPF, Shortest Process First)算法”
是否可抢占?:SJF和SPF是非抢占式的算法。但是也有抢占式的版本一—最短剩余时间优先算法(SRTN, Shortest Remaining Time Next)
最短剩余时间优先算法:每当有进程加入就绪队列改变时就需要调度,如果新到达的进程剩余时间比当前运行的进程剩余时间更短,则由新进程抢占处理机,当前运行进程重新回到就绪队列。另外,当一个进程完成时也需要调度
优缺点:
- 优点:“最短的”平均等待时间、平均周转时间
- 缺点:不公平。对短作业有利,对长作业不利。可能产生饥饿现象。另外,作业/进程的运行时间是由用户提供的,并不一定真实,不一定能做到真正的短作业优先
是否会导致饥饿:会。如果源源不断地有短作业/进程到来,可能使长作业/进程长时间得不到服务,产生“饥饿”现象。如果一直得不到服务,则称为“饿死“。
高响应比优先(HRRN,Highest Response Ratio Next)
算法思想:要综合考虑作业/进程的等待时间和要求服务的时间
算法规则:在每次调度时先计算各个作业/进程的响应比,选择响应比最高的作业/进程为其服务
用于作业/进程调度:即可用于作业调度,也可用于进程调度
是否可抢占?:非抢占式的算法。因此只有当前运行的作业/进程主动放弃处理机时,才需要调度,才需要计算响应比
注:这几种算法主要关心对用户的公平性、平均周转时间、平均等待时间等评价系统整体性能的指标,但是不关心“响应时间”,也并不区分任务的紧急程度,因此对于用户来说,交互性很糟糕。因此这三种算法一般适合用于早期的批处理系统,当然,FCFS算法也常结合其他的算法使用,在现在也扮演着很重要的角色。