集群目的就是为了实现rabbitmq的高可用性,集群分为2种
- 普通集群:主备架构,只是实现主备方案,不至于主节点宕机导致整个服务无法使用
- 镜像集群:同步结构,基于普通集群实现的队列同步
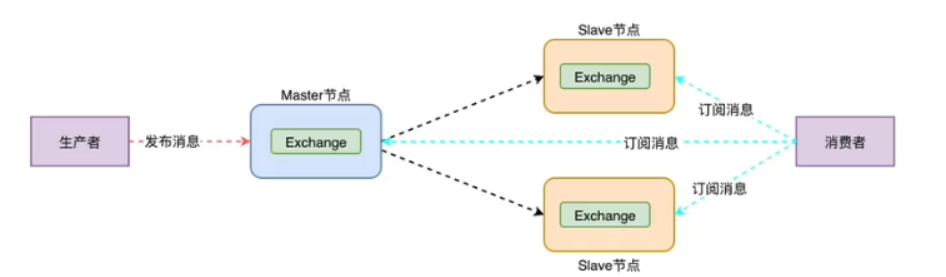
普通集群
slave节点复制master节点的所有数据和状态,除了队列数据,队列数据只存在master节点,但是Rabbitmq slave节点可以实现队列的转发,也就是说消息消费者可以连接到slave节点,但是slave需要连接到master节点转发队列,由此说明只能保证了服务可以用,无法达到高可用。slave节点队列可以查看到,但是不会同步数据。
![]()
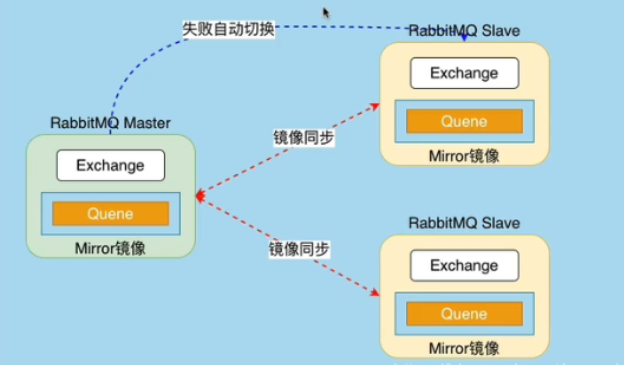
镜像集群
基于普通集群实现队列的集群主从,消息会在集群中同步(至少三个节点)
![]()
一、前期准备
以三台服务为例,首先三台服务器都修改映射文件,域名映射,方便访问
vi /etc/hosts
192.168.1.11 mq1
192.168.1.12 mq2
192.168.1.13 mq3
单机安装,在三台服务器上独立安装rabbitmq服务,并确认安装成功,参考:RabbitMq单机安装
- 192.168.1.11
- 192.168.1.12
- 192.168.1.13
二、拷贝cookie文件
RabbitMQ的集群是依赖erlang集群,而erlang集群是通过这个cookie进行通信认证的,因此我们搭集群的第一步就是处理cookie。怎么办?必须使集群中也就是这3台机器的.erlang.cookie文件中cookie值一致,且权限为owner只读。rpm安装的erlang,直接去/var/lib/rabbitmq目录看!建议直接scp其中一个节点的.erlang.cookie文件到另外两个节点即可!
将mq1服务器上的cookie文件,同步拷贝到mq2、mq3,注意需要先将mq2、mq3服务暂停。
scp /var/lib/rabbitmq/.erlang.cookie mq2:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie mq3:/var/lib/rabbitmq/
修改 cookie 文件,要重启 linux 服务器mq1,mq2、mq3执行 reboot命令,可以看到节点名称
经测试修改cookie重启后通过rabbitmqctl命令添加的用户权限将失效,需要重新添加
![]()
三、开放4369端口
先把三台机器的防火墙先关了,如果你不想关,可以关闭各自的4369集群通信端口
#关闭防火墙
systemctl stop firewalld
-----------------------------------------------------------------------------
#开启端口,其他端口照做
firewall-cmd --zone=public --add-port=4369/tcp --permanent
#重启防火墙
firewall-cmd --reload
#查看端口号是否开启
firewall-cmd --query-port=4369/tcp
#测试是否可以访问虚拟机端口
telnet 192.168.223.128 4369
四、加入集群节点
例如将节点mq2,mq3加入节点mq1。在节点mq2,mq3上执行如下命令:
[root@mq4 ~]# rabbitmqctl stop_app
Stopping rabbit application on node rabbit@mq4 ...
[root@mq4 ~]# rabbitmqctl join_cluster rabbit@mq1
Clustering node rabbit@mq4 with rabbit@mq1
[root@mq4 ~]# rabbitmqctl start_app
Starting node rabbit@mq4 ...
注意:rabbitmqctl stop和rabbitmqctl stop_app的区别,rabbitmqctl stop命令会停止RabbitMQ的Erlang虚拟机和RabbitMQ应用服务,rabbitmqctl stop_app只是停止RabbitMQ应用,不停止Erlang虚拟机。
查看集群状态,可以发现节点已经加入集群
[root@mq1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@mq1 ...
Basics
Cluster name: rabbit@mq1
Disk Nodes
rabbit@mq1
rabbit@mq2
rabbit@mq3
Running Nodes
rabbit@mq1
rabbit@mq2
rabbit@mq3
Versions
rabbit@mq1: RabbitMQ 3.9.10 on Erlang 23.3.4.6
rabbit@mq2: RabbitMQ 3.9.10 on Erlang 23.3.4.6
rabbit@mq3: RabbitMQ 3.9.10 on Erlang 23.3.4.6
Maintenance status
Node: rabbit@mq1, status: not under maintenance
Node: rabbit@mq2, status: not under maintenance
Node: rabbit@mq3, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@mq1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@mq1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@mq1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@mq2, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@mq2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@mq2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@mq3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@mq3, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@mq3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: stream_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
五、从集群中移除节点
要移除某节点,首先需要停止节点的运行,在节点所在服务器执行:
rabbitmqctl stop_app
在主节点执行:
rabbitmqctl forget_cluster_node rabbit@mq3
这样mq3节点就被移除了
六、集群节点类型
从查看集群状态输出的信息中,可以看到:
Disk Nodes
rabbit@mq1
rabbit@mq2
rabbit@mq3
这表明目前集群中的三个节点都是磁盘节点。RabbitMQ中的每一个节点,不管是单一节点系统或者是集群中的一部分,要么是内存节点(arm),要么是磁盘节点(disc)。
内存节点将所有的队列、交换器、绑定关系、用户、权限和 vhost 的元数据定义都存储在内存中。而磁盘节点会将这些信息都存储到磁盘中。
单节点的集群中,必然只有磁盘类型的节点,否则当重启 Rabbit MQ后,所有关于系统的配置信息都会丢失。
设置节点类型
加入集群时设置:
rabbitmqctl join_cluster rabbit@mq1 --ram
已经加入集群时修改:
先停止节点服务,在修改,最后启动服务
[root@mq2 ~]# rabbitmqctl stop_app
[root@mq2 ~]# rabbitmqctl change_cluster_node_type ram
[root@mq2 ~]# rabbitmqctl start_app
在集群中创建队列、交换器和绑定关系时,这些操作都需要集群中所有节点都成功提交元数据才会返回。内存节点会存入内存,磁盘节点会写入磁盘。内存节点有着出色的性能,磁盘节点可以提供高可靠性。
Rabbit MQ 要求在集群中至少有一个磁盘节点,其他的节点可以内存节点。当节点加入或离开集群时,必须将信息通知到至少一个磁盘节点。
假如说,集群中只有一个磁盘节点,而恰巧不巧这个磁盘节点服务崩溃了,那么对于集群来说,仍然可以继续接受或发送消息,但是不能进行创建队列、交换器、绑定关系、用户,以及更改权限、添加和删除节点的操作。在磁盘节点恢复之前是无法执行任何更改操作的。所以,在集群中至少要有两个磁盘节点或者更多。
内存节点重启后,会先连接到磁盘节点,拷贝当前集群的配置的元数据副本。当有内存节点添加到集群时,会通知集群所有的磁盘节点。内存节点唯一写入磁盘的元数据信息就是集群中是磁盘节点的地址。只要内存节点可以找到至少一个磁盘节点,那么就能在重启后加入集群。
为了保证集群的可靠性,或者不确定是使用磁盘节点还是内存节点时,建议全部选择磁盘节点。
七、镜像模式
将所有队列设置为镜像队列,即队列会被复制到各个节点,各个节点状态一致。
语法:set_policy {NAME} {PATTERN} {DEFINITION}
- NAME - 策略名,可自定义
- PATTERN - 队列的匹配模式(正则表达式)
- ^ 可以使用正则表达式,比如 ^queue 表示对队列名称以 queue 开头的所有队列进行镜像,而 ^ 会匹配所有的队列。
- DEFINITION - 镜像定义,包括三个部分 ha-mode, ha-params, ha-sync-mode
- ha-mode - high available 高可用模式,指镜像队列的模式,有效值为 all/exactly/nodes;当前策略模式为 all,即复制到所有节点,包含新增节点。all 表示在集群中所有的节点上进行镜像;exactly 表示在指定个数的节点上进行镜像,节点的个数由 ha-params 指定;nodes 表示在指定的节点上进行镜像,节点名称通过 ha-params 指定。
- ha-params - ha-mode 模式需要用到的参数。
- ha-sync-mode - 进行队列中消息的同步方式,有效值为 automatic 和 manual。
执行命令:
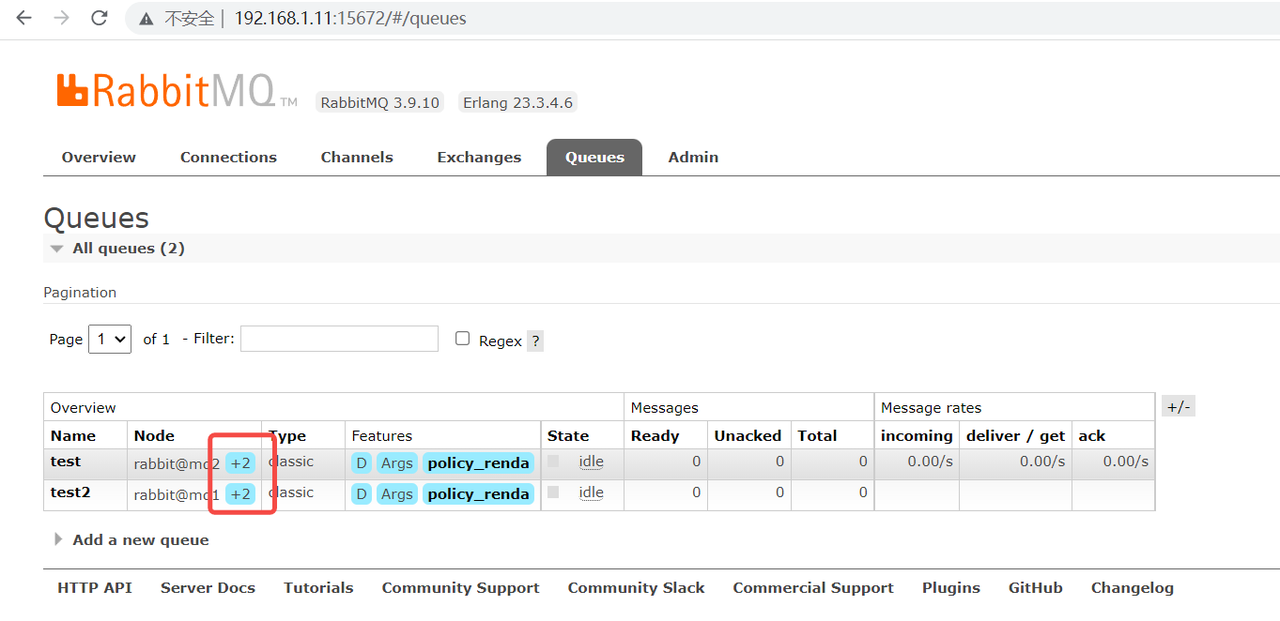
rabbitmqctl set_policy policy_renda "^" '{"ha-mode":"all"}'
会看到队列会镜像到其他节点
![]()