一、什么是protobuf?
在移动互联网时代,手机流量、电量是最为有限的资源,而移动端的即时通讯应用无疑必须得直面这两点。
解决流量过大的基本方法就是使用高度压缩的通信协议,而数据压缩后流量减小带来的自然结果也就是省电:因为大数据量的传输必然需要更久的网络操作、数据序列化及反序列化操作,这些都是电量消耗过快的根源。
当前即时通讯应用中最热门的通信协议无疑就是Google的Protobuf了,基于它的优秀表现,微信和手机QQ这样的主流IM应用也早已在使用它。
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。支持多种开发语言:C++、Java、Python、Objective-C、C#、JavaNano、JavaScript、Ruby、Go、PHP,基本上主流的语言都已支持。
Protocol Buffers和xml,json一样都是消息传输过程中的一种编码方式、或协议,它和xml、json相比主要的优点就是内容更少,传输更快,解析更快。
二、优缺点:
- 优点:空间效率搞,时间效率要高,对于数据大小敏感,传输效率高的
- 缺点:消息结构可读性不高,序列化后的字节序列为二进制序列不能简单的分析有效性;
三、Ptotocol buffers下载安装与配置:
Windows为例:
官网地址:https://github.com/protocolbuffers/protobuf/releases
![]()
解压后将文件中的bin目录配置到path环境变量中:
![]()
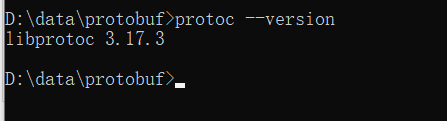
命令窗口中执行:protoc --version 会出现版本信息,则说明配置成功
![]()
四、编写proto文件
编写proto文件,生成对应对的类。
创建Person.proto文件
syntax = "proto3"; // proto3 必须加此注解
option java_package = "com.weblog"; // 生成类的包名,注意:会在指定路径下按照该包名的定义来生成文件夹
option java_outer_classname="WeblogPerson"; // 生成类的类名,注意:下划线的命名会在编译的时候被自动改为驼峰命名
message Person {
string name = 1;
int32 age = 2;
int32 height = 3;
int32 weight = 4;
enum Sex {
GIRL = 0;
BOY = 1;
}
Sex sex = 5;
message Phone{
string number = 1;
string isp = 2;
}
Phone phone = 6;
}
在文件所在目录的cmd窗口中执行如下命令:protoc -I=./ --java_out=./ ./Person.proto
配置的包下会生成java文件
![]()
命令参数:
- -I 等价于 -proto_path:指定 .proto 文件所在的路径
- --java_out:编译成 java 文件时,文件输出目标路径,如果是c++则参数为--cpp_out
- ./Person.proto:指定需要编译的 .proto 文件
把java文件放到项目中就可以使用了,当然要引入对应的版本的pom文件
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.17.3</version>
</dependency>
五、java为例何如使用
package com.weblog;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import java.io.ByteArrayInputStream;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
WeblogPerson.Person.Builder person = WeblogPerson.Person.newBuilder();
person.setName("张三");
person.setAge(12);
person.setHeight(150);
person.setSex(WeblogPerson.Person.Sex.GIRL);
WeblogPerson.Person.Phone.Builder phone = WeblogPerson.Person.Phone.newBuilder();
phone.setNumber("1867678976");
phone.setIsp("移动");
person.setPhone(phone);
//方案1:序列化和反序列化
//序列化
// byte[] bytes = person.build().toByteArray();
// //反序列化
// WeblogPerson.Person p = WeblogPerson.Person.parseFrom(bytes);
// System.out.println(p.getAge());
// System.out.println(p.getSex());
//方案2:ByteString
//序列化
// ByteString bytes2 = person.build().toByteString();
// System.out.println(bytes2);
// //反序列化
// WeblogPerson.Person p2 = WeblogPerson.Person.parseFrom(bytes2);
// System.out.println(p2.getSex());
//方案3:InputStream
ByteArrayInputStream inputStream = new ByteArrayInputStream(person.build().toByteArray());
WeblogPerson.Person p3 = WeblogPerson.Person.parseFrom(inputStream);
inputStream.close();
System.out.println(p3.getSex());
}
}
看完这个简单的例子之后,希望您已经能理解 Protobuf 能做什么了,那么您可能会说,世上还有很多其他的类似技术啊,比如 XML,JSON,Thrift 等等。和他们相比,Protobuf 有什么不同呢?
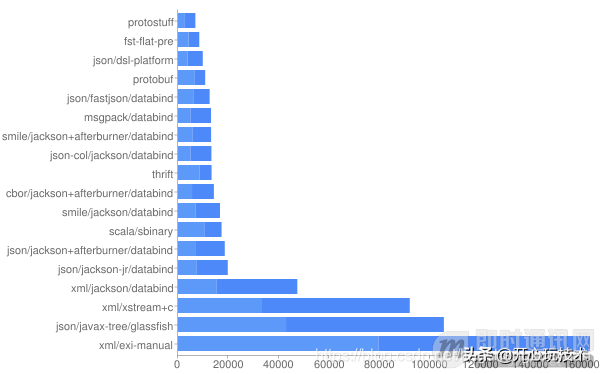
简单说来 Protobuf 的主要优点就是:简单,快。这有测试为证,项目 thrift-protobuf-compare 比较了这些类似的技术,图 1 显示了该项目的一项测试结果,Total Time.
![]()
Total Time 指一个对象操作的整个时间,包括创建对象,将对象序列化为内存中的字节序列,然后再反序列化的整个过程。从测试结果可以看到 Protobuf 的成绩很好。
更多参考:https://github.com/eishay/jvm-serializers/wiki